unicode编码英文字符和中文字符
什么是Unicode编码
Unicode是一种字符编码标准,旨在为世界上所有的文字和符号提供一个唯一的编码方案。它可以处理各种语言和符号,包括英文字符和中文字符,确保在全球范围内的信息传递不会出现乱码的问题。Unicode让不同语言的字符能够在同一平台上被识别和使用,极大地方便了多语言的交流。
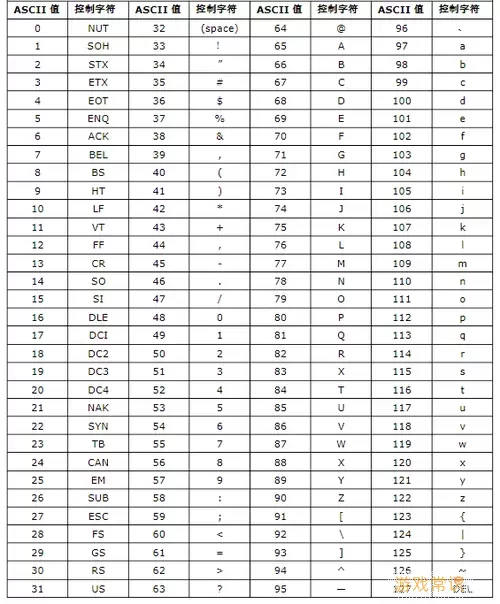
在Unicode中,英文字符的编码范围是U+0000到U+007F。这个范围涵盖了基本的拉丁字母、数字以及一些特殊符号。例如,字母A的Unicode编码是U+0041,字母Z的编码是U+005A。通过Unicode编码,英文字符能够在任何操作系统和设备上保持一致性和可识别性。
中文字符的Unicode编码
中文字符的Unicode编码范围较大,主要分布在U+4E00到U+9FFF之间。这个范围内包含了常用汉字,适用于简体和繁体中文。此外,还有一些扩展汉字的编码,分布在其他区域,如U+3400到U+4DBF和U+20000到U+2A6DF等。Unicode的使用确保了中文字符在互联网上的正确显示和传输。
Unicode编码的优点
Unicode编码的最大优点在于它的统一性和兼容性。无论是在不同的操作系统、编程语言还是网络环境中,Unicode都能提供一致的字符表示方式。这使得开发者在处理多语言内容时,能够避免字符转换的复杂性和潜在错误,从而提高了软件的国际化能力。
如何使用Unicode编码
在编程过程中,使用Unicode编码非常简单。在大多数编程语言中,可以通过转义序列来插入Unicode字符。例如,在JavaScript中,可以使用\u后跟四位十六进制数字来表示Unicode字符。此外,许多文本编辑器和IDE也支持直接输入Unicode字符,使得开发和编辑变得更加方便。
总的来说,Unicode编码为字符的全球化使用提供了坚实的基础。无论是英文字符还是中文字符,通过Unicode,用户和开发者都能轻松处理各种语言的信息。因此,掌握Unicode编码对于现代软件开发和跨国交流来说显得尤为重要。