完整Python爬虫教程:主动爬取小说目录与内容
随着互联网的发展,越来越多的人选择在网上阅读小说。爬虫技术也因此走入了大众的视野,成为了很多程序员学习的热门主题。本文将为大家提供一个完整的Python爬虫教程,介绍如何主动爬取小说的目录与内容,让你轻松获取网络小说资源。
一、环境准备
在开始之前,我们需要安装必要的Python库。首先确保你的计算机上安装了Python,如果未安装,可以前往Python官网进行下载。
接着,打开命令行工具,输入以下命令安装爬虫所需的库:
pip install requests beautifulsoup4
其中,requests库用于发送网络请求,beautifulsoup4用于解析HTML文档,方便我们提取所需数据。
二、分析网站结构
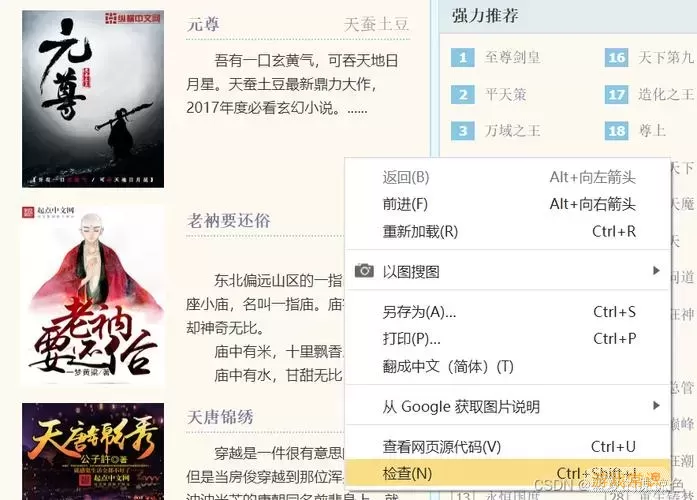
在爬取小说之前,我们需要先了解目标网站的结构。以某个常见的小说网站为例,我们可以通过浏览器的“查看页面源代码”功能来分析页面。通常情况下,小说的目录会在一个特定的HTML标签中,比如或标签,而每本小说的章节链接则可能在标签中。
确定了数据所在的标签后,我们就可以编写爬虫代码了。
三、编写爬虫代码
以下是一个简单的示例代码,用于爬取小说目录及其章节内容:
import requests
from bs4 import BeautifulSoup
# 爬取小说目录
def fetch_novel_directory(url):
response = requests.get(url)
response.encoding = utf-8 # 确保中文正常显示
soup = BeautifulSoup(response.text, html.parser)
# 假设目录在一个名为list的标签中
directory = soup.find(ul, class_=list)
chapters = directory.find_all(a)
chapter_list = {}
for chapter in chapters:
chapter_title = chapter.get_text()
chapter_url = chapter[href]
chapter_list[chapter_title] = chapter_url
return chapter_list
# 爬取章节内容
def fetch_chapter_content(chapter_url):
response = requests.get(chapter_url)
response.encoding = utf-8
soup = BeautifulSoup(response.text, html.parser)
# 假设章节内容在一个名为content的标签中
content = soup.find(p, class_=content)
return content.get_text()
# 主程序
if __name__ == __main__:
novel_url = http://example.com/novel # 替换为目标小说的URL
directory = fetch_novel_directory(novel_url)
for title, url in directory.items():
print(f章节:{title})
content = fetch_chapter_content(url)
print(content)
print(- * 80)
这个简单的爬虫能够抓取小说的目录和每个章节的内容,信息输出到控制台。你可以根据需要将数据保存到文件或数据库中。
四、注意事项
在爬取网站数据时,请务必遵循以下原则:
尊重网站的robots.txt协议,避免对服务器造成过大的压力。
合理设置爬取频率,尽量避免短时间内发送大量请求。
遵循版权法规,不要随意复制和传播爬取内容。
本文介绍了利用Python进行小说爬虫的基本步骤,包括环境准备、网站结构分析以及一些简单的代码示例。掌握这些基础知识后,你可以根据实际需求,进一步扩展和优化你的爬虫程序。
爬虫技术是一个非常有趣的领域,希望本文能让你对Python爬虫有一个初步的了解,激发你进一步学习的兴趣。在实践中不断优化自己的代码,积累经验,相信你一定能够成为一名优秀的爬虫开发者。