unicode和utf-8的关系
什么是Unicode?
Unicode是一种字符编码标准,旨在为世界上所有的书写系统提供统一的编码方法。它包含了几乎所有已知的字符和符号,包括拉丁字母、汉字、阿拉伯字母、标点符号等。Unicode的出现使得不同的平台和设备之间能够更好地进行文本交换,消除了以往字符编码不兼容带来的问题。
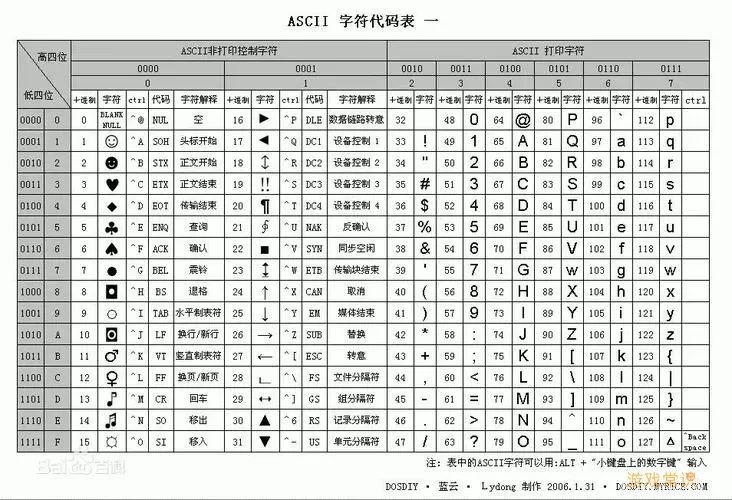
UTF-8是一种可变长度的字符编码方案,它是Unicode的一种实现方式。UTF-8能够使用1到4个字节来表示Unicode中的每一个字符,这使得UTF-8在处理英文字符时非常高效,因为它的ASCII字符(0-127)的编码与ASCII完全相同。这种设计使得UTF-8可以无缝地与旧版ASCII处理系统兼容。
Unicode与UTF-8的关系
Unicode与UTF-8之间的关系可以说是标准与实现的关系。Unicode是一个广泛的字符集规范,而UTF-8则是实现这个规范的一种方法。当我们提到Unicode时,实际上是在谈论一个庞大的字符集,而UTF-8则是用来在计算机系统中存储和传输这些字符的一种具体编码方案。
UTF-8的优点
UTF-8有很多优点,使其成为现代web和应用程序的标准编码格式。首先,UTF-8能够很好地兼容ASCII,这意味着很多老旧系统和程序无需更改即可支持Unicode字符。其次,由于UTF-8是可变长编码,对于使用拉丁字母的文本,它能够节省存储空间。此外,UTF-8的设计还使得它在网络传输中极为高效,这也使得它成为互联网的主流编码格式。
使用UTF-8的注意事项
在使用UTF-8编码时,需要确保所有的系统组件(如数据库、服务器、前端页面等)都一致使用UTF-8编码,以避免字符编码不一致导致的问题。同时,开发者需要了解在不同编程语言和框架中如何正确处理UTF-8字符串,以确保数据的完整性和正确性。
Unicode和UTF-8在现代计算机科学中占据着重要的地位。Unicode为全球字符提供了统一的编码方案,而UTF-8则是这个标准在实际使用中的一种高效、兼容的实现方式。了解它们的关系和特性,有助于更好地进行文本处理和数据交换。